graph TD; A[r_training] --> B[scripts]; A --> C[data]; A --> D[outputs];
Importação, Organização e Exportação de Dados
Treinamento em R
Boas Práticas na Organização de Projetos
Ao iniciar uma nova análise, organize seu trabalho criando um sistema estruturado de pastas:
📁
r_training📁
scripts/(código)📁
data/(conjuntos de dados)📁
outputs/(resultados como gráficos, tabelas, etc.)
Nota
Use minúsculas e hífens (-) em vez de espaços ao nomear pastas, arquivos e objetos em R para manter consistência e facilitar o gerenciamento.
Entendendo Caminhos de Pastas
- Um caminho é um endereço que indica ao software onde encontrar um arquivo ou pasta no seu computador.
Dois Tipos de Caminhos:
- Caminho Absoluto:
/Users/yourname/Desktop/r_training - Caminho Relativo:
r_training/scripts
A Vantagem de Usar Projetos
O R não sabe automaticamente onde seus arquivos estão. Usar um projeto RStudio cria um atalho que informa ao R onde encontrar tudo, tornando seu fluxo de trabalho mais suave.
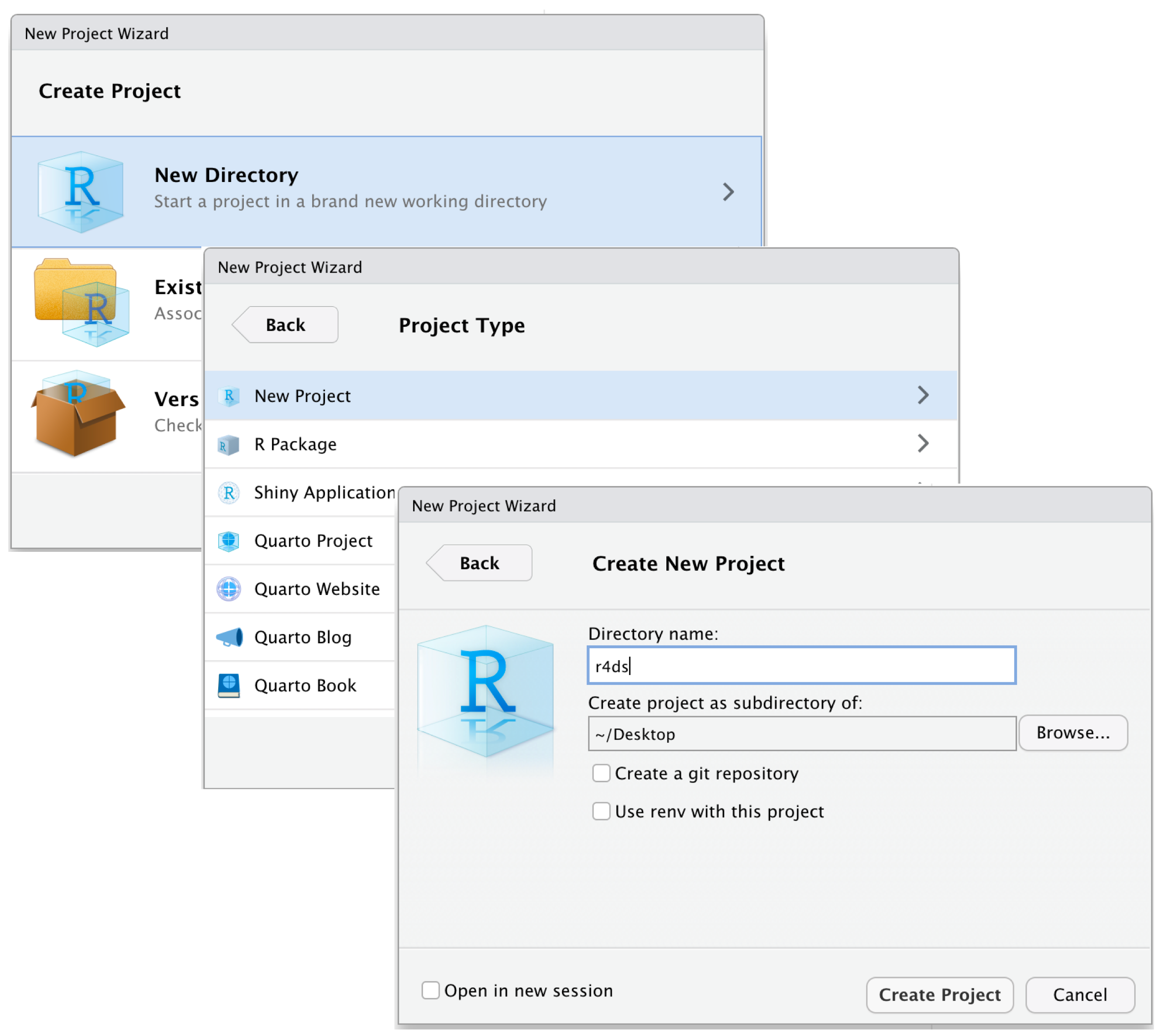
Configurando Seu Ambiente
05:00 Crie uma nova Pasta chamada
r_trainingCrie um Projeto
- Abra o RStudio.
- Vá para File > New Project > Existing Directory.
- Navegue até sua pasta
r_traininge clique em Open.
- Clique em Create Project para finalizar.
Abra o Projeto (Clique duas vezes no arquivo para abri-lo no RStudio.)
Execute este comando no Console do RStudio:
- Siga as instruções para descompactar os materiais na pasta do seu projeto.
Você está pronto para começar! 🎉
Organizando a Pasta data
graph TD; A[data] --> B[Raw]; A --> C[Intermediate]; A --> D[Final];
Raw
- Dados originais, intocados.
- Backup recomendado para preservar a integridade.
Intermediate
- Dados formatados, renomeados e organizados.
- Pronto para limpeza adicional.
Final
- Dados limpos e transformados.
- Pronto para gráficos, tabelas e regressões.
Importar
Preparando Dados para R: Conceitos Gerais e Melhores Práticas
Tipos de Documento organizações dependem extensivamente de planilhas (ler)
Formatos de dados comuns incluem:
Planilhas (.csv, .xlsx, xls…): Padrão para dados estruturados.
DTA (.dta): Usado para dados do STATA.
Planilhas
CSV é geralmente preferível:
Mais fácil de importar e processar.
Mais compatível em diferentes sistemas e softwares e muito mais leve.
Avançado
O formato Apache Arrow é projetado para lidar com grandes conjuntos de dados de forma eficiente, tornando-o adequado para análise de big data. Arquivos Arrow oferecem operações de leitura/escrita mais rápidas em comparação com formatos tradicionais.
Importando Dados para R
Exercício 1: Importação de Dados
Você pode encontrar o exercício na pasta “Exercises/exercise_01_template.R”
10:00 Suas tarefas:
Carregar pacotes usando
pacmanImportar três conjuntos de dados:
firm_characteristics.csv(usefread)vat_declarations.dta(useread_dta)
cit_declarations.xlsxplanilha 2 (useread_excel)
- Para cada conjunto de dados:
- Exibir as primeiras 5 linhas
- Verificar nomes das colunas
- Limpar nomes com
janitor::clean_names()
- Bônus: Certifique-se de que as colunas de ID da empresa tenham o mesmo nome em todos os conjuntos de dados
Exercício 1: Soluções
# Carregar pacotes
packages <- c("readxl", "dplyr", "tidyverse", "data.table", "here", "haven", "janitor")
if (!require("pacman")) install.packages("pacman")
pacman::p_load(packages, character.only = TRUE, install = TRUE)
# Carregar características das empresas
dt_firms <- fread(here("Data", "Raw", "firm_characteristics.csv"))
head(dt_firms, 5)
names(dt_firms)
dt_firms <- clean_names(dt_firms)
# Carregar declarações de IVA
panel_vat <- read_dta(here("Data", "Raw", "vat_declarations.dta"))
head(panel_vat, 5)
names(panel_vat)
# Carregar declarações de CIT
panel_cit <- read_excel(here("Data", "Raw", "cit_declarations.xlsx"), sheet = 2)
head(panel_cit, 5)
names(panel_cit)
# Bônus: Garantir nomenclatura consistente
panel_vat <- rename(panel_vat, firm_id = id_firm) # se necessárioInspecionando Dados
Inspecionando Seus Dados: Primeira Olhada
- Uma vez que os dados são importados, primeiro queremos dar uma olhada neles 👀
# A tibble: 6 × 7
`Taxpayer ID` Name `Tax Filing Year` `Taxable Income` `Tax Paid` Region
<chr> <chr> <dbl> <dbl> <dbl> <chr>
1 TX001 John Doe 2020 89854 8985 North
2 TX001 John Doe 2021 65289 6528 North
3 TX001 John Doe 2022 87053 8705 North
4 TX001 John Doe 2023 58685 5868 North
5 TX002 Jane Smith 2020 97152 9715 South
6 TX002 Jane Smith 2021 62035 6203 South
# ℹ 1 more variable: `Payment Date` <dttm># A tibble: 6 × 7
`Taxpayer ID` Name `Tax Filing Year` `Taxable Income` `Tax Paid` Region
<chr> <chr> <dbl> <dbl> <dbl> <chr>
1 TX009 Olivia King 2022 91276 9127 North
2 TX009 Olivia King 2023 90487 9048 North
3 TX010 Liam Scott 2020 50776 5077 South
4 TX010 Liam Scott 2021 86257 8625 South
5 TX010 Liam Scott 2022 52659 5265 South
6 TX010 Liam Scott 2023 76665 7666 South
# ℹ 1 more variable: `Payment Date` <dttm>Nota
Você também pode notar que as colunas Taxpayer ID e Full Name estão cercadas por crases. Isso ocorre porque elas contêm espaços, o que quebra as regras padrão de nomenclatura do R, tornando-as nomes não sintáticos. Para se referir a essas variáveis em R, você precisa colocá-las entre crases.
Inspecionando Seus Dados: Dimensões
- Verificar as dimensões dos seus dados:
Inspecionando Seus Dados: Estrutura
- Obter nomes de colunas e examinar a estrutura dos dados:
[1] "Taxpayer ID" "Name" "Tax Filing Year" "Taxable Income"
[5] "Tax Paid" "Region" "Payment Date" [1] "Taxpayer ID" "Name" "Tax Filing Year" "Taxable Income"
[5] "Tax Paid" "Region" "Payment Date" tibble [40 × 7] (S3: tbl_df/tbl/data.frame)
$ Taxpayer ID : chr [1:40] "TX001" "TX001" "TX001" "TX001" ...
$ Name : chr [1:40] "John Doe" "John Doe" "John Doe" "John Doe" ...
$ Tax Filing Year: num [1:40] 2020 2021 2022 2023 2020 ...
$ Taxable Income : num [1:40] 89854 65289 87053 58685 97152 ...
$ Tax Paid : num [1:40] 8985 6528 8705 5868 9715 ...
$ Region : chr [1:40] "North" "North" "North" "North" ...
$ Payment Date : POSIXct[1:40], format: "2020-01-31" "2021-12-31" ...Inspecionando Seus Dados: Melhor Visualização da Estrutura
- Vamos obter uma melhor visão geral da estrutura e conteúdo dos dados:
Rows: 40
Columns: 7
$ `Taxpayer ID` <chr> "TX001", "TX001", "TX001", "TX001", "TX002", "TX002"…
$ Name <chr> "John Doe", "John Doe", "John Doe", "John Doe", "Jan…
$ `Tax Filing Year` <dbl> 2020, 2021, 2022, 2023, 2020, 2021, 2022, 2023, 2020…
$ `Taxable Income` <dbl> 89854, 65289, 87053, 58685, 97152, 62035, 60378, 876…
$ `Tax Paid` <dbl> 8985, 6528, 8705, 5868, 9715, 6203, 6037, 8768, 9368…
$ Region <chr> "North", "North", "North", "North", "South", "South"…
$ `Payment Date` <dttm> 2020-01-31, 2021-12-31, 2022-01-31, 2023-04-30, 202…Dica
glimpse() é como str() mas mais legível! Mostra tipos de dados, primeiros valores e se ajusta bem ao seu console.
Inspecionando Seus Dados: Estatísticas Resumidas
- Gerar estatísticas resumidas para todas as colunas:
Taxpayer ID Name Tax Filing Year Taxable Income
Length:40 Length:40 Min. :2020 Min. :50438
Class :character Class :character 1st Qu.:2021 1st Qu.:58748
Mode :character Mode :character Median :2022 Median :78590
Mean :2022 Mean :75504
3rd Qu.:2022 3rd Qu.:90287
Max. :2023 Max. :98140
Tax Paid Region Payment Date
Min. :5043 Length:40 Min. :2020-01-31 00:00:00
1st Qu.:5874 Class :character 1st Qu.:2021-04-23 06:00:00
Median :7858 Mode :character Median :2022-01-15 12:00:00
Mean :7550 Mean :2022-01-02 09:00:00
3rd Qu.:9028 3rd Qu.:2023-01-07 18:00:00
Max. :9814 Max. :2023-11-30 00:00:00 Dica
summary() é incrivelmente útil! Para variáveis numéricas, mostra mínimo, máximo, média, mediana e quartis. Para variáveis de caractere, mostra comprimento e classe.
Limpando Nomes de Colunas
- Agora, vamos garantir que nossos nomes de variáveis sigam a convenção snake_case 😎
- Opção 1: Renomear colunas manualmente:
- Opção 2: Converter automaticamente todos os nomes de colunas para snake_case usando janitor:
[1] "taxpayer_id" "name" "tax_filing_year" "taxable_income"
[5] "tax_paid" "region" "payment_date" Exercício 2: Inspecionando Dados
Você pode encontrar o exercício na pasta “Exercises/exercise_02_template.R”
10:00 Suas tarefas:
Usando os três conjuntos de dados que você importou no Exercício 1:
- Para
dt_firms:
- Verificar dimensões (linhas e colunas)
- Usar
glimpse()para examinar a estrutura - Gerar estatísticas resumidas
- Para
panel_vat:
- Exibir as primeiras 10 linhas
- Verificar número de empresas únicas
- Encontrar nomes de colunas
- Para
panel_cit:
- Exibir as últimas 5 linhas
- Verificar se há valores ausentes usando
summary()
Exercício 2: Soluções
# Carregar pacotes necessários
library(dplyr)
library(data.table)
# 1. Inspecionar dt_firms
dim(dt_firms)
glimpse(dt_firms)
summary(dt_firms)
# 2. Inspecionar panel_vat
head(panel_vat, 10)
length(unique(panel_vat$firm_id))
names(panel_vat)
# 3. Inspecionar panel_cit
tail(panel_cit, 5)
summary(panel_cit)Escrevendo Dados em R
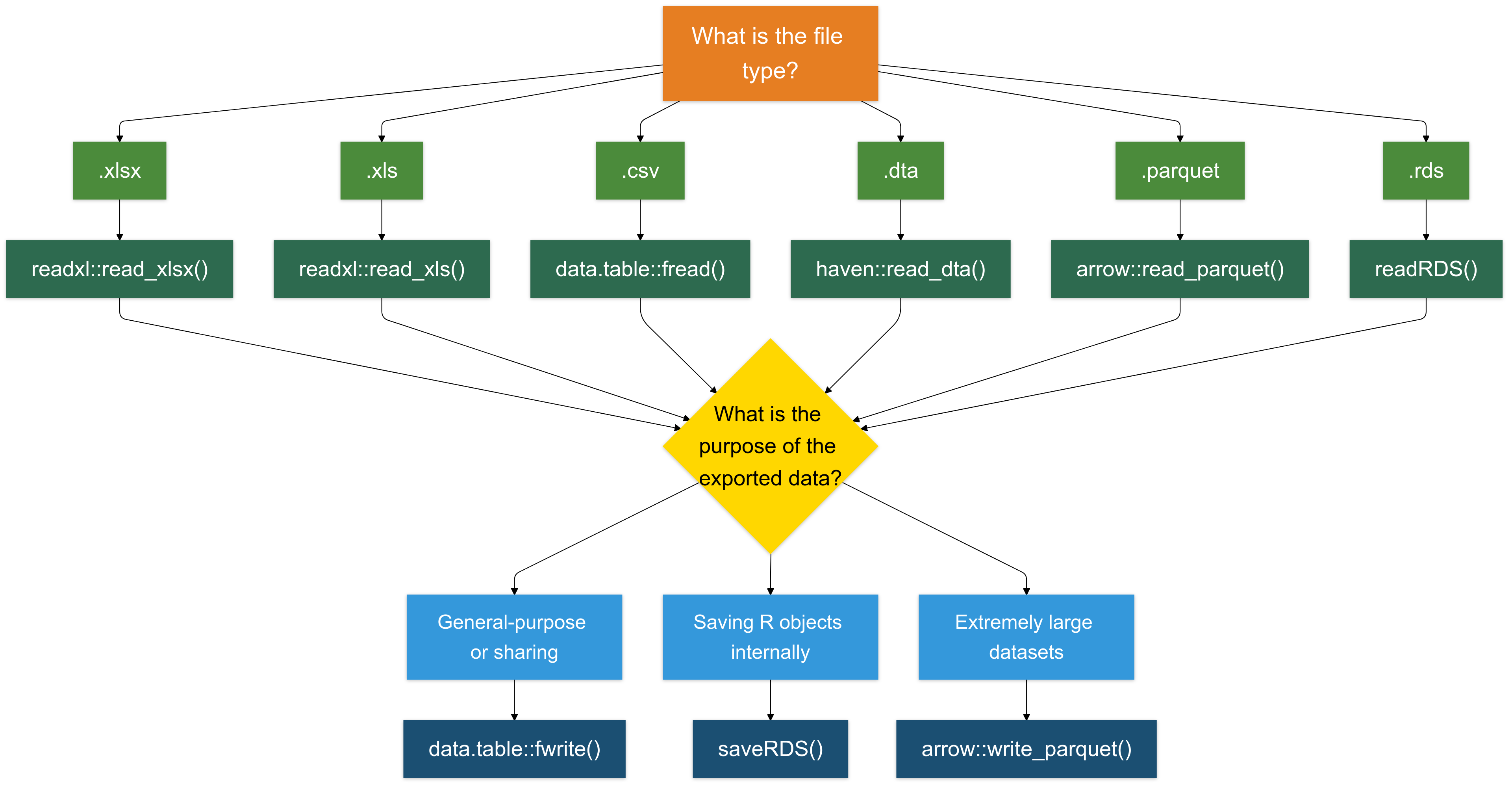
Escrever em Formato .csv é (Quase) Sempre uma Boa Escolha
Para a maioria dos casos, escrever dados em formato .csv é uma opção confiável e amplamente compatível.
Recomendo usar a função
fwritedo pacotedata.tablepor sua velocidade e eficiência.
- Abaixo, salvamos vários conjuntos de dados na pasta Intermediate usando fwrite:
# Escrever os Dados de IVA
fwrite(panel_vat, here("quarto_files", "Solutions", "Data", "Intermediate", "panel_vat.csv"))
# Escrever as Declarações de CIT
fwrite(panel_cit, here("quarto_files", "Solutions", "Data", "Intermediate", "panel_cit.csv"))
# Escrever as Características das Empresas
fwrite(dt_firms, here("quarto_files", "Solutions", "Data", "Intermediate", "dt_firms.csv"))Existem outras opções para escrever dados
Escrevendo Arquivos .rds (Para Objetos R)
O formato .rds é especificamente projetado para salvar objetos R. É útil para salvar resultados intermediários, objetos ou dados.
Exploraremos este formato com mais detalhes mais tarde, mas aqui está um exemplo rápido:
- Escrevendo Arquivos .xlsx (Para Compatibilidade com Excel): Para salvar dados em formato Excel (.xlsx), use o pacote writexl. É leve e não requer dependências externas.
- Escrevendo Arquivos .parquet (Para Grandes Conjuntos de Dados): O formato .parquet é um formato de armazenamento colunar que é altamente eficiente tanto para leitura quanto para escrita de grandes conjuntos de dados (tipicamente >1GB).
Para Resumir
Exercício 3: Escrever Dados Limpos
Você pode encontrar o exercício na pasta “Exercises/exercise_03_template.R”
05:00 Suas tarefas:
Salvar os três conjuntos de dados limpos em diferentes formatos:
Características das empresas → CSV
Salvar comodata/intermediate/firms_clean.csvusandofwrite()Declarações de IVA → RDS
Salvar comodata/intermediate/vat_clean.rdsusandosaveRDS()Declarações de CIT → Parquet
Salvar comodata/intermediate/cit_clean.parquetusandowrite_parquet()Bônus: Por que escolhemos formatos diferentes para cada conjunto de dados?
Exercício 3: Soluções
# Carregar pacotes necessários
library(data.table)
library(arrow)
library(here)
# Salvar características das empresas como CSV
fwrite(dt_firms, here("data", "intermediate", "firms_clean.csv"))
# Salvar declarações de IVA como RDS
saveRDS(panel_vat, here("data", "intermediate", "vat_clean.rds"))
# Salvar declarações de CIT como Parquet
write_parquet(panel_cit, here("data", "intermediate", "cit_clean.parquet"))
# Resposta Bônus:
# dt_firms (CSV): Dados de referência, legível por humanos, compartilhado entre departamentos
# panel_vat (RDS): Preserva tipos de dados R, carregamento mais rápido em fluxos de trabalho R
# panel_cit (Parquet): Armazenamento colunar eficiente para grandes conjuntos de dados em painelBônus: Conectando R a Bancos de Dados
- Por que Conectar a Bancos de Dados?
- Os dados são frequentemente armazenados em bancos de dados centralizados para maior segurança, acessibilidade e gerenciamento.
- Fluxos de trabalho tradicionais podem envolver o envio de solicitações de dados às equipes de TI, causando atrasos e flexibilidade limitada para analistas.
- O Poder do
Rpara Acesso a Bancos de Dados
- Usando
R, você pode: - Consultar dados diretamente e em tempo real.
- Importar grandes conjuntos de dados perfeitamente para seu ambiente
R.
Aviso
No entanto, sugiro extrair os dados usando sua interface SQL e depois trabalhar com os dados extraídos em R.
Exemplo: conectando a um banco de dados
# Carregar Pacotes
library(DBI) # este pacote é sempre necessário
library(RMariaDB) # existem pacotes para cada tipo de banco de dados (ex. MySQL, PostgreSQL, etc.)
# Estabelecer uma conexão com o banco de dados
con <- dbConnect(
MariaDB(),
host = "database.server.com",
user = "your_username",
password = "your_password",
dbname = "tax_database"
)
# Consultar o banco de dados
tax_data <- dbGetQuery(con, "SELECT * FROM vat_declarations WHERE year = 2023")
# Desconectar quando terminar
dbDisconnect(con)